merge.ai is your gateway to the latest advancements in generative AI technology. Our app offers seamless access to cutting-edge models from top-tier AI providers, including OpenAI, Anthropic, Stability.ai, and more.
With merge.ai, you can effortlessly interact with the newest generative AI tools available. Whether you’re looking to enhance your productivity with sophisticated chat completions or create compelling visual content through image and video generation, our platform provides an extensive suite of tools designed to meet your needs.
merge.ai gives you access to the latest models available without the need to individually subscribe to every provider and pay monthly fees. With our pay-as-you-go strategy you only pay for the tokens/credits you actually use.
Find out all available models, its providers and prices visiting our pricing page.
Experience the future of AI today with merge.ai, where innovation meets convenience.
Documentation
We’re working hard to ensure that our documentation keeps up with our growing community. If you have a question we encourage you to start with the documentation (right here!). If you can’t find what you’re looking for, please visit one of our support channels.
Getting support
Users can get support through the following channels:
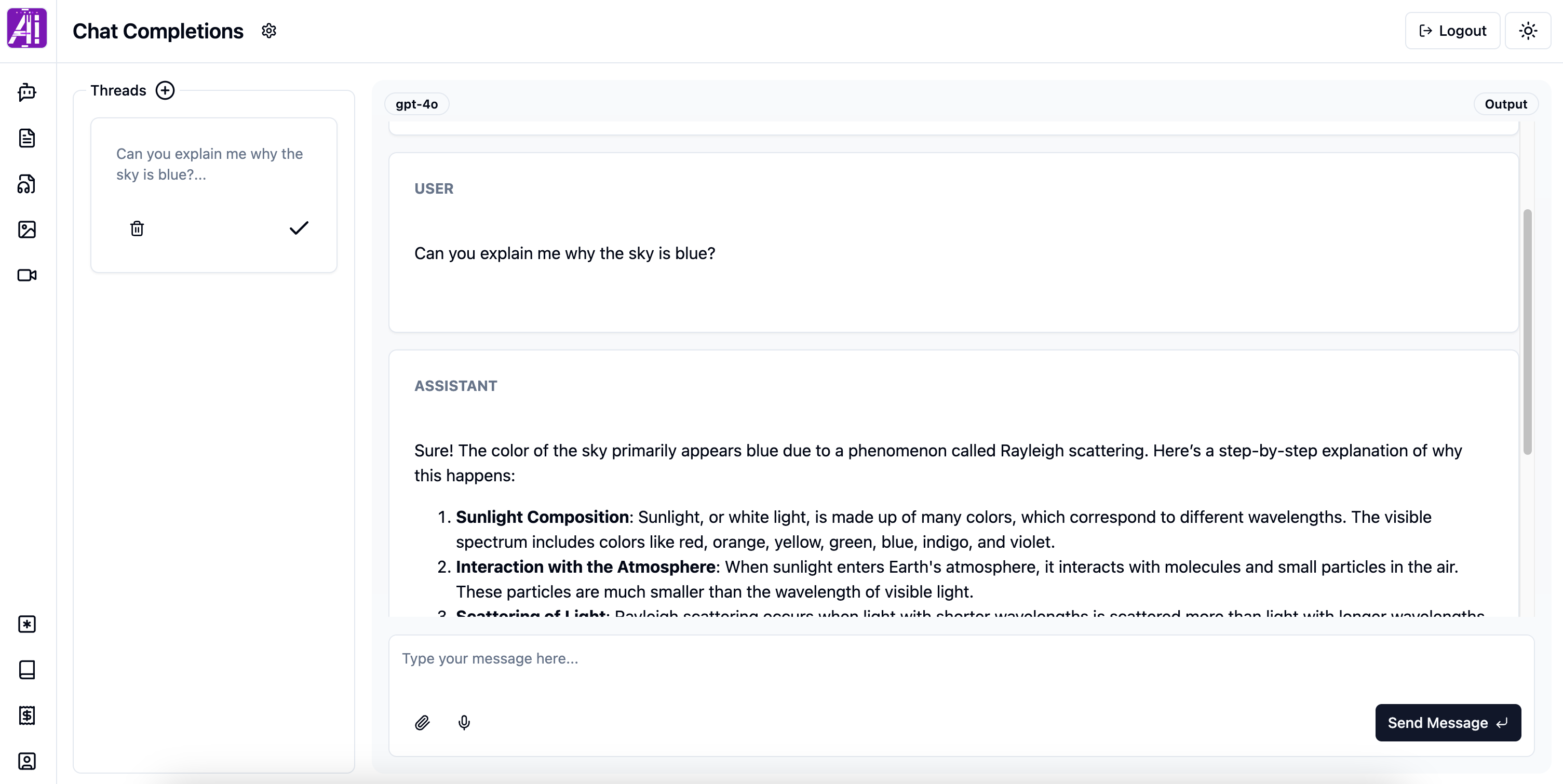
The Chat Completions area is the first page you see after logging in to merge.ai.
The navigation bar (at the left of the screen) is the same on every screen in merge.ai. It contains links which give you quick access to many of merge.ai’s areas.
The header bar (at the top of the screen) contains area-specific functions plus the Logout and Light/Dark Theme buttons.
Chat Completions is where you interact via text, or image (when available) with the most advanced LLMs (Large Language Models) on the market.
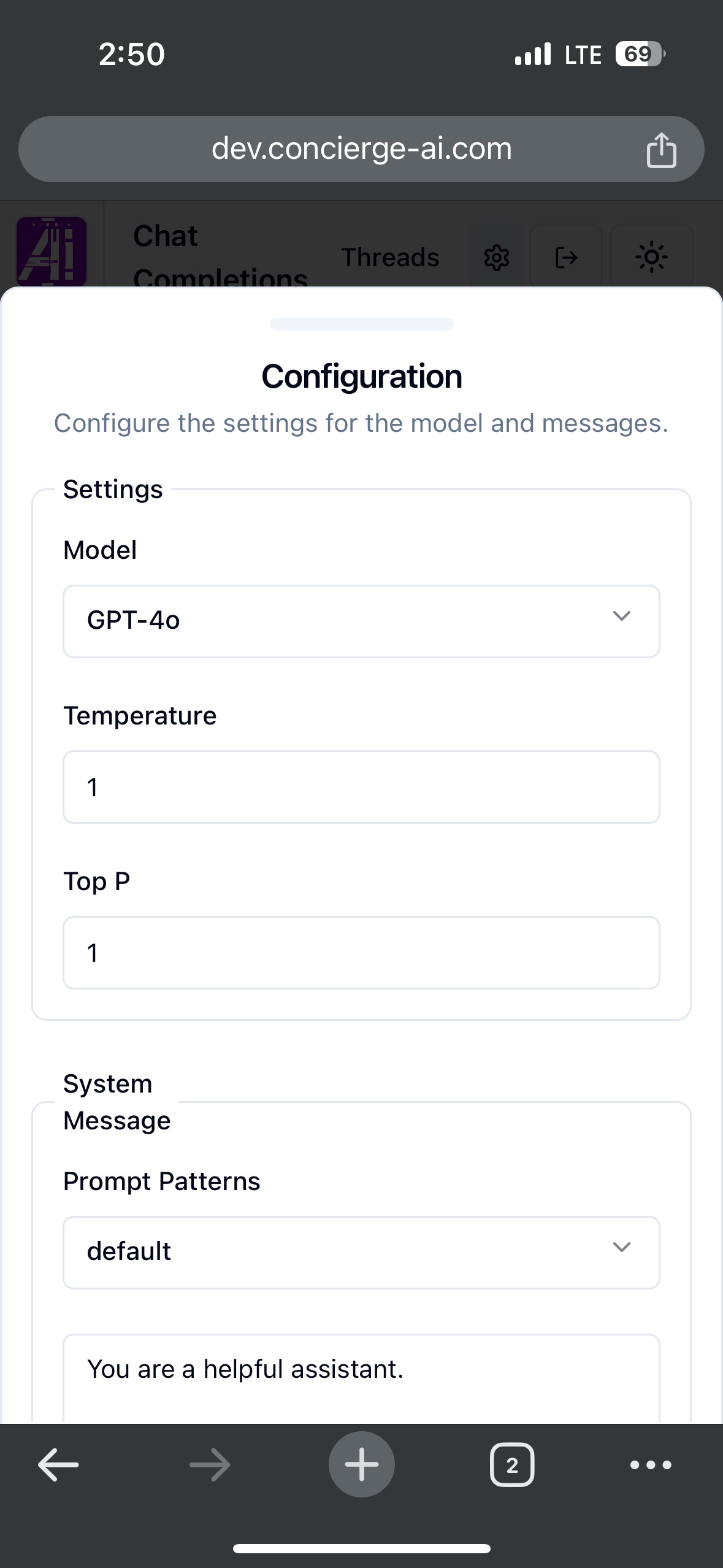
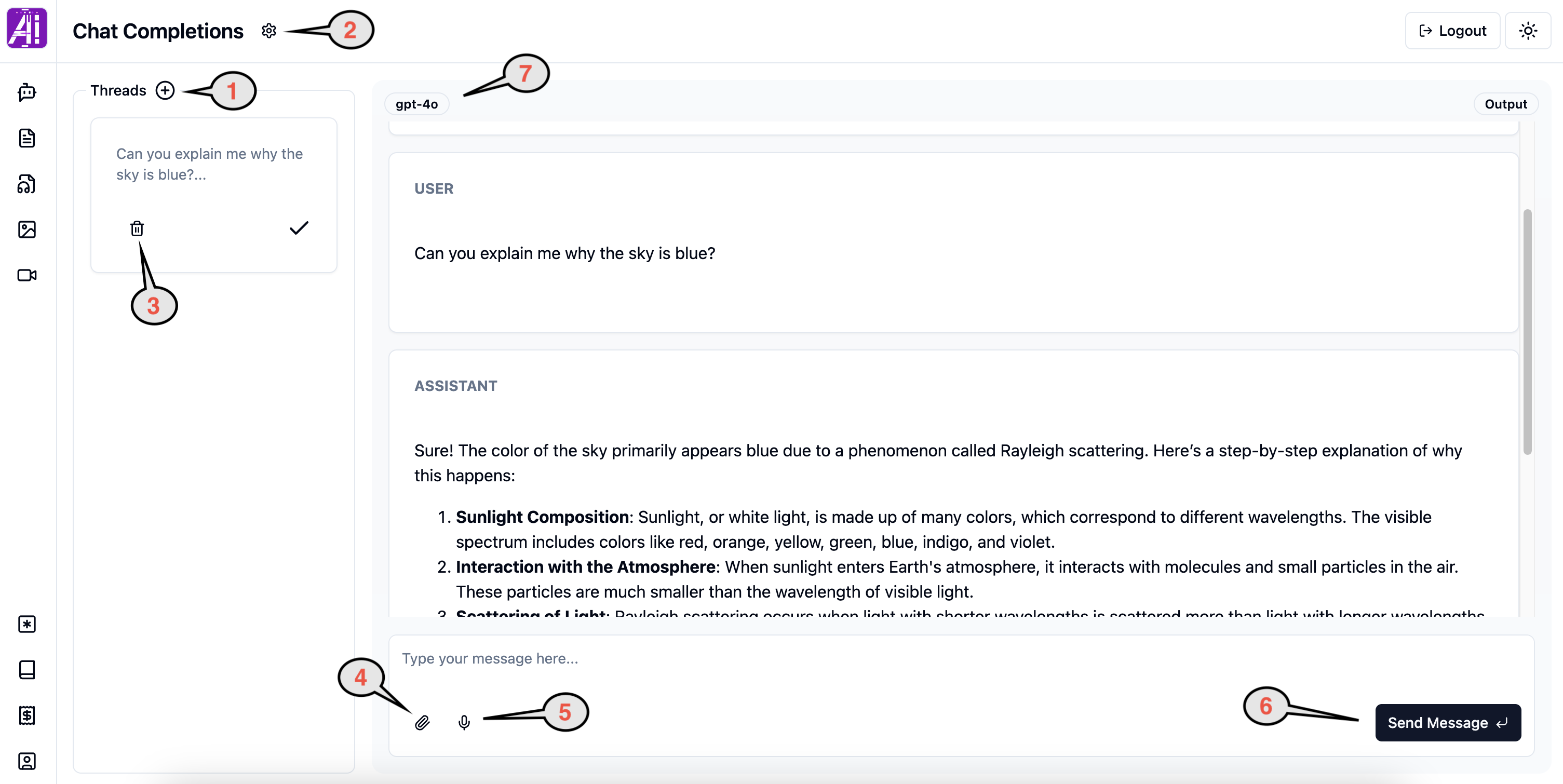
The easiest way to start is by selecting a Thread (by clicking on it) and start typing your messages. If you don’t have any Threads, create one by using the “add” button (1).
If you want to change the model or advanced options click on the “gear” (2). More details at Configuring Chat Completions.
You can only type/send your message (6), attach file (4) or dictate (5) when a Thread is selected.
If the selected Model is capable of ingest images, the “attach file (4)” option will be available.
Threads
Threads are a group of Chat Messages. You can think of Threads being the subject of a conversation, holding all related messages that belongs to that subejct.
You can create up to 100 Threads but only the first 50 will be shown at the Threads browser on the left side of the screen.
Chat Messages
Each chat message has a role (either system, user, or assistant) and content.
The system message is optional and can be used to set the behavior of the assistant
The user messages provide requests or comments for the assistant to respond to
Assistant messages is the answer from the model
By default, the system message is “You are a helpful assistant”. You can define instructions in the user message, but the instructions set in the system message are more effective. You can only set one system message per Thread.
You can check the selected LLM Model by looking at the Selected Model Chip (7).
Differently from the system message wich is unique per Thread, the LLM Model can be changed at any time. That means you can start a chat with Model “A” and continue the same chat with Model “B”.
Chat Completions pricing is based on token usage. You can think of tokens as pieces of words used for natural language processing. For more details visit What is a token?.
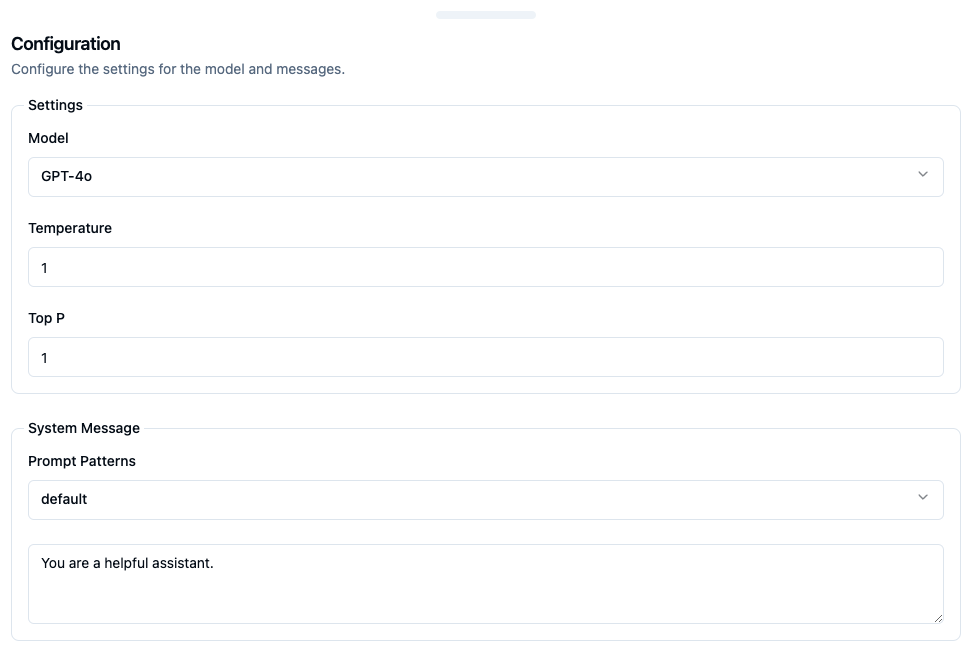
Temperature value controls the output balance between coherence and creativity. Lower values for temperature result in more consistent outputs (e.g. 0.2), while higher values generate more diverse and creative results (e.g. 1.0). The default value is 1.
Top P or nucleus sampling is a setting that decides how many possible words to consider. A high “Top P” value means the model looks at more possible words, even the less likely ones, which makes the generated text more diverse.
The System Message is a special input provided to the model to steer its behavior and set the context for its interactions. Its primary purpose is to define guidelines, tone, or instructions on how the model should respond to user inputs. This helps ensure that the generated outputs are aligned with the desired objectives and constraints.
The default message is “You are a helpful assistant” and there are two ways of changing it:
Typing your desired System Message at the input text field
Choose a pre-defined Prompt Pattern from the “Prompt Patterns” drop-down menu
Temperature is a parameter that controls randomness when picking words during text creation. Low values of temperature make the text more predictable and consistent, while high values let more freedom and creativity into the mix, but can also make things less consistent. Temperature can vary from 0 to 1.
Temperature closer to 0: Responses are very predictable, always choosing the next most likely word. This is great for answers where facts and accuracy are really important.
Temperature closer to 1: The model takes more chances, picking words that are less likely, which can lead to more creative but unpredictable answers.
Examples of Temperature
Temperature = 0: If you ask, “What are the benefits of exercising?”, with a temperature of 0, the model might say: “Exercising improves heart health and muscle strength, lowers the chance of chronic diseases, and helps manage weight.”
Temperature = 1: With the same question on exercise and a temperature of 1, you might get: “Exercise is the alchemist turning sweat into a miracle cure, a ritual dancing in the flames of effort and reward.”
Top P or nucleus sampling is a parameter that decides how many possible words to consider. A high “Top P” value means the model looks at more possible words, even the less likely ones, which makes the generated text more diverse. Top P can vary from 0 to 1.
Top P = 0.5: The model considers words that together add up to at least 50% of the total probability, leaving out the less likely ones and keeping a good level of varied responses.
Top P = 0.9: The model includes a lot more words in the choice, allowing for more variety and originality.
Examples of Top P
Top P = 0.5: If you ask for a title for an adventure book, with a top-p of 0.5, the model might come up with: “The Mystery of the Blue Mountain.”
Top P = 0.9: For the same adventure book title and a top-p of 0.9, the model might create: “Voices from the Abyss: A Portrait of the Brave.”
Mixing Temperature and Top P can give a wide range of text styles. A low Temperature with a high Top P can lead to coherent text with creative touches. On the other hand, a high Temperature with a low Top P might give you common words put together in unpredictable ways.
Low Temperature and High Top P
Model outputs are usually logical and consistent because of the low Temperature, but they can still have rich vocabulary and ideas due to the high Top P. This setup is good for educational or informative texts where clarity is crucial, but you also want to keep the reader’s interest.
High Temperature and Low Top P
Model outputs often results in texts where sentences may make sense on their own but as a whole seem disconnected or less logical. The high Temperature allows more variation in sentence building, while the low Top P limits word choices to the most likely ones. This can be useful in creative settings where you want unexpected results or to spark new ideas with unusual concept combinations.
The choice of Temperature and Top P depends on your needs and the overall context. For content that needs to be very reliable and precise, like legal documents or technical reports, a lower Temperature is better. For creative work, like fiction writing or advertising, playing with higher values for both settings might be a good idea.